一、引言
在构建高性能Go应用时,内存使用效率往往是决定应用质量的关键因素。就像一个整洁高效的工作空间能提升工作效率一样,合理的内存管理能让程序运行更加流畅。内存使用不当不仅会导致程序运行缓慢,还可能引发OOM(Out Of Memory)错误,让用户体验大打折扣。
为什么内存基准测试如此重要? 想象你正在驾驶一辆汽车,没有油表,你永远不知道何时会耗尽燃料。同样,没有内存基准测试,你的应用可能在关键时刻因内存问题而崩溃。通过基准测试,我们能够:
本文面向已具备Go语言基础,希望深入了解内存性能优化的开发者和架构师。阅读完本文,你将能够设计并执行有效的内存基准测试,掌握常见内存优化技巧,并将这些知识应用到实际项目中。
二、Go内存管理基础回顾
在深入基准测试前,让我们先回顾Go语言的内存管理机制。这就像了解汽车引擎工作原理,才能更好地提升燃油效率。
Go内存分配机制简述
Go使用一种称为TCMalloc(Thread-Caching Malloc)的内存分配器变种。这个分配器将内存分为三个层次:
┌─────────────────────────────────────┐
│ Go内存分配体系 │
├─────────────┬──────────┬────────────┤
│ mcache │ mcentral │ mheap │
│ (线程本地缓存) │ (全局缓存) │ (堆内存管理) │
└─────────────┴──────────┴────────────┘
堆与栈的使用策略
Go编译器会尽可能将变量分配在栈上,这称为栈分配。只有当变量可能在函数返回后仍被引用时,才会分配到堆上,这就是所谓的堆分配或内存逃逸。
重要提示:栈分配比堆分配效率高得多!栈内存随函数返回自动释放,无需GC介入。
我们可以通过以下命令查看变量的分配位置:
go build -gcflags="-m -l" main.go
GC工作原理及触发条件
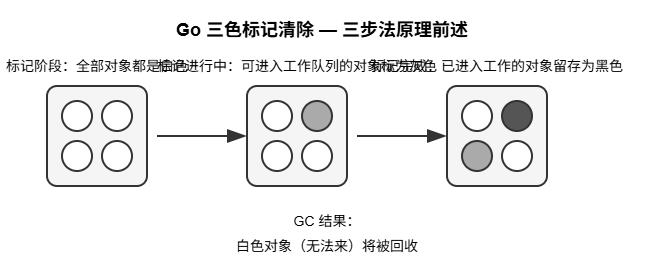
Go使用三色标记-清除算法进行垃圾回收:
标记阶段:将所有对象标记为白色,从根对象开始遍历,将可达对象标记为灰色,然后黑色清除阶段:回收所有仍为白色的对象
GC触发条件主要有:
三、基准测试工具介绍
掌握合适的工具是进行有效内存基准测试的前提,就像木匠需要合适的工具才能打造精美家具一样。
Go内置testing包的基准测试能力
Go的testing包提供了强大的基准测试框架,使用起来简单直观:
// bench_test.go
package example
import "testing"
func BenchmarkExample(b *testing.B) {
// 可选:在计时开始前进行初始化
data := make([]int, 1000)
// 重置计时器
b.ResetTimer()
// 执行 b.N 次被测试的代码
for i := 0; i < b.N; i++ {
// 要测试的代码
for j := 0; j < len(data); j++ {
data[j] = j
}
}
}
运行基准测试:
# -benchmem 显示内存分配统计信息
go test -bench=. -benchmem
输出示例:
BenchmarkExample-8 10000 152032 ns/op 8192 B/op 1 allocs/op
这里的关键指标:
pprof工具的使用与分析
pprof是Go提供的性能分析利器,可以生成内存使用的详细报告。
开启内存profile收集:
import (
"os"
"runtime/pprof"
// 其他导入
)
func main() {
// 创建内存profile文件
f, _ := os.Create("mem.pprof")
defer f.Close()
// 开始记录内存分配情况
pprof.WriteHeapProfile(f)
// 你的程序逻辑
}
对于HTTP服务,可以直接使用net/http/pprof:
import _ "net/http/pprof" // 仅需导入,无需显式使用
分析内存profile:
go tool pprof -http=:8080 mem.pprof
这将在浏览器中打开可视化界面,包含多种视图:
第三方内存分析工具对比
除了官方工具,还有几款优秀的第三方工具值得关注:
工具名称特点适用场景
go-torch
基于pprof的火焰图生成工具,视觉效果出色
直观分析内存热点
memory-profiler
实时内存监控,支持历史数据对比
长期运行的服务内存趋势分析
goimports
静态分析,发现可能的内存问题
代码审查阶段
goleak
检测goroutine泄漏问题
并发程序测试
实践建议:将pprof集成到CI/CD流程中,对每次代码提交进行内存基准检测,及早发现问题。
四、内存基准测试的关键指标
理解和选择合适的指标,就像医生知道该检查哪些身体指标一样重要。以下是进行内存基准测试时需要关注的核心指标:
内存分配次数(allocs)
内存分配次数直接影响程序性能。每次分配都需要与内存分配器交互,如果频繁分配小对象,会导致性能下降。
理想状态:尽可能减少分配次数,特别是在热路径上。
// 不佳示例:循环中频繁分配
func BadExample() string {
var result string
for i := 0; i < 100; i++ {
// 每次循环都会分配新内存
result += fmt.Sprintf("%d", i)
}
return result
}
// 优化示例:使用strings.Builder减少分配
func GoodExample() string {
var builder strings.Builder
for i := 0; i < 100; i++ {
fmt.Fprintf(&builder, "%d", i)
}
return builder.String()
}
内存分配大小(bytes)
程序总共分配了多少内存,以及单次操作的分配量。
分析维度:
GC压力评估
GC(垃圾回收)压力过大会导致程序周期性卡顿,影响用户体验。
关键指标:
监控GC:
import "runtime/debug"
func init() {
// 设置GC日志记录
debug.SetGCPercent(100) // 默认为100,越小GC越频繁
// 将GC信息导出到文件
f, _ := os.Create("gc.log")
debug.SetGCTrace(f)
}
内存泄漏检测方法
内存泄漏是指程序分配的内存没有被正确释放,导致内存占用持续增长。
检测方法:
长时间运行测试:观察内存使用是否持续增长周期性触发GC:检查GC后内存是否下降使用pprof监控对象数量:关注某类对象是否异常增多
// 强制触发GC并观察内存使用情况
func checkMemoryLeak() {
var m runtime.MemStats
// 先获取当前内存状态
runtime.ReadMemStats(&m)
beforeHeap := m.HeapAlloc
// 强制GC
runtime.GC()
// 再次获取内存状态
runtime.ReadMemStats(&m)
afterHeap := m.HeapAlloc
// 计算GC后内存减少量
reduction := float64(beforeHeap - afterHeap) / float64(beforeHeap) * 100
log.Printf("内存减少: %.2f%%n", reduction)
}
五、实战案例:常见数据结构的内存效率比较
在实际开发中,选择合适的数据结构对内存效率至关重要。就像选择合适的容器可以最大化存储空间一样,正确的数据结构能显著提升内存使用效率。
下面我们通过基准测试对比几种常见数据结构的内存使用情况:
package datastructure
import (
"testing"
)
// BenchmarkSliceVsMap 对比切片和Map在查找操作中的内存效率
func BenchmarkSliceVsMap(b *testing.B) {
// 切片查找基准测试
b.Run("slice-lookup", func(b *testing.B) {
// 准备含有1000个元素的切片
data := make([]int, 1000)
for i := 0; i < 1000; i++ {
data[i] = i
}
// 查找目标值
target := 500
b.ResetTimer() // 重置计时器,不计算初始化时间
for i := 0; i < b.N; i++ {
// 线性查找
found := false
for _, v := range data {
if v == target {
found = true
break
}
}
// 防止编译器优化掉查找操作
if !found {
b.Fatal("Value not found")
}
}
})
// Map查找基准测试
b.Run("map-lookup", func(b *testing.B) {
// 准备含有1000个元素的Map
data := make(map[int]bool, 1000)
for i := 0; i < 1000; i++ {
data[i] = true
}
// 查找目标值
target := 500
b.ResetTimer() // 重置计时器,不计算初始化时间
for i := 0; i < b.N; i++ {
// 常数时间查找
if _, found := data[target]; !found {
b.Fatal("Value not found")
}
}
})
}
// BenchmarkStringManipulation 对比字符串处理方法的内存效率
func BenchmarkStringManipulation(b *testing.B) {
// 使用+运算符拼接字符串
b.Run("string-concat", func(b *testing.B) {
for i := 0; i < b.N; i++ {
var s string
for j := 0; j < 100; j++ {
s += "a"
}
}
})
// 使用strings.Builder拼接字符串
b.Run("strings-builder", func(b *testing.B) {
for i := 0; i < b.N; i++ {
var builder strings.Builder
for j := 0; j < 100; j++ {
builder.WriteByte('a')
}
_ = builder.String()
}
})
// 使用byte切片拼接字符串
b.Run("byte-slice", func(b *testing.B) {
for i := 0; i < b.N; i++ {
bs := make([]byte, 0, 100)
for j := 0; j < 100; j++ {
bs = append(bs, 'a')
}
_ = string(bs)
}
})
}
运行结果分析:
切片vs映射的对比结果
BenchmarkSliceVsMap/slice-lookup-8 1000000 1223 ns/op 0 B/op 0 allocs/op
BenchmarkSliceVsMap/map-lookup-8 10000000 125 ns/op 0 B/op 0 allocs/op
结论分析:
字符串处理方法对比结果
BenchmarkStringManipulation/string-concat-8 20000 82450 ns/op 57488 B/op 99 allocs/op
BenchmarkStringManipulation/strings-builder-8 300000 4210 ns/op 168 B/op 1 allocs/op
BenchmarkStringManipulation/byte-slice-8 200000 6150 ns/op 256 B/op 1 allocs/op
结论分析:
️ 警告:在循环中使用+拼接字符串是内存使用的大忌!总是使用strings.Builder代替。
表格比较不同数据结构的内存特性:
数据结构内存效率适用场景注意事项
切片(Slice)
紧凑连续,低开销
有序数据,频繁追加
预分配容量避免频繁扩容
映射(Map)
哈希表结构,有额外开销
键值查询,无序数据
预估容量初始化,减少rehash
数组(Array)
固定大小,零额外开销
大小确定的小数据集
大数组作为参数会复制
链表(List)
每节点有指针开销
频繁在中间插入/删除
节点分配多,GC压力大
strings.Builder
动态扩容,低分配次数
字符串拼接
重用Builder可进一步优化
六、项目实战:API服务内存优化案例
理论知识需要在实战中检验。下面分享一个真实的API服务内存优化案例。
问题背景:高并发API服务内存占用过高
我们的团队开发了一个产品目录API服务,随着业务增长,服务器内存使用持续攀升,高峰期甚至触发OOM(内存不足)告警。监控显示即使在业务低谷期,内存占用也没有明显下降,这表明可能存在内存泄漏或使用效率低下的问题。
服务特点:
基准测试设计与执行
首先,我们为核心API端点编写了基准测试,模拟真实流量:
// api_benchmark_test.go
func BenchmarkProductListAPI(b *testing.B) {
// 设置请求参数
params := url.Values{}
params.Add("category", "electronics")
params.Add("limit", "50")
b.ResetTimer()
for i := 0; i < b.N; i++ {
resp := httptest.NewRecorder()
req, _ := http.NewRequest("GET", "/api/products?"+params.Encode(), nil)
// 执行请求
router.ServeHTTP(resp, req)
// 验证响应状态
if resp.Code != http.StatusOK {
b.Fatalf("Expected status 200, got %d", resp.Code)
}
}
}
我们还开启了pprof采集内存信息,并在持续1小时的负载测试后生成了内存使用报告。
性能瓶颈发现:大对象分配与字符串拼接
pprof分析揭示了主要问题:
JSON序列化占用过多内存:每个请求都会分配大量临时对象重复产品数据在内存中有多份副本大量字符串拼接使用低效方法大对象没有复用,每次请求都重新分配
内存分配Top5函数:
Showing top 5 functions by memory allocation:
51.8% json.Marshal
17.2% productService.GetProductDetail
12.5% fmt.Sprintf
8.3% productService.FormatProductDescription
5.1% ioutil.ReadAll
优化方案及效果对比
针对发现的问题,我们实施了以下优化:
1. JSON优化
// 优化前:每次序列化都分配新内存
func (s *Server) handleGetProduct(w http.ResponseWriter, r *http.Request) {
product := s.repo.GetProduct(id)
data, _ := json.Marshal(product) // 每次创建新的内存
w.Write(data)
}
// 优化后:使用对象池和预分配缓冲区
var jsonBufferPool = sync.Pool{
New: func() interface{} {
return bytes.NewBuffer(make([]byte, 0, 4096))
},
}
func (s *Server) handleGetProduct(w http.ResponseWriter, r *http.Request) {
product := s.repo.GetProduct(id)
// 从对象池获取缓冲区
buf := jsonBufferPool.Get().(*bytes.Buffer)
buf.Reset()
defer jsonBufferPool.Put(buf)
// 直接写入缓冲区,避免中间分配
encoder := json.NewEncoder(buf)
encoder.Encode(product)
w.Write(buf.Bytes())
}
2. 数据结构优化
// 优化前:产品结构包含大量冗余信息
type Product struct {
ID int64
Name string
Description string
Images []Image // 每个图片含大量元数据
Attributes map[string]string
// 其他大量字段...
}
// 优化后:根据API需求定制输出结构
type ProductSummary struct {
ID int64 `json:"id"`
Name string `json:"name"`
ImageURLs []string `json:"images"` // 只存URL,不存元数据
// 其他必要字段...
}
// 视图转换函数
func ToSummary(p *Product) *ProductSummary {
urls := make([]string, 0, len(p.Images))
for _, img := range p.Images {
urls = append(urls, img.URL)
}
return &ProductSummary{
ID: p.ID,
Name: p.Name,
ImageURLs: urls,
}
}
3. 字符串处理优化
// 优化前:大量使用+和Sprintf
func formatProductDescription(p *Product) string {
result := "Product: " + p.Name + "n"
result += "Category: " + p.Category + "n"
result += fmt.Sprintf("Price: $%.2fn", p.Price)
// 更多拼接...
return result
}
// 优化后:使用strings.Builder
func formatProductDescription(p *Product) string {
var b strings.Builder
// 预估容量,避免扩容
b.Grow(len(p.Name) + len(p.Category) + 50)
b.WriteString("Product: ")
b.WriteString(p.Name)
b.WriteString("nCategory: ")
b.WriteString(p.Category)
fmt.Fprintf(&b, "nPrice: $%.2fn", p.Price)
// 更多拼接...
return b.String()
}
4. 应用sync.Pool减少GC压力
// 为频繁使用的大型临时对象创建对象池
var (
productSlicePool = sync.Pool{
New: func() interface{} {
return make([]*Product, 0, 100)
},
}
responseBufferPool = sync.Pool{
New: func() interface{} {
return new(ApiResponse)
},
}
)
func (s *Server) handleListProducts(w http.ResponseWriter, r *http.Request) {
// 从对象池获取产品切片
products := productSlicePool.Get().([]*Product)
products = products[:0] // 清空但保留容量
defer productSlicePool.Put(products)
// 从对象池获取响应结构
resp := responseBufferPool.Get().(*ApiResponse)
defer responseBufferPool.Put(resp)
// 填充数据
products = s.repo.ListProducts(category, products)
resp.Products = products
resp.Total = len(products)
// 序列化和响应
// ...
}
优化效果
优化前后的内存使用对比:
指标优化前优化后改进
平均内存使用
2.8 GB
0.9 GB
-67.9%
每请求内存分配
215 KB
46 KB
-78.6%
GC频率
每30秒
每2分钟
-75.0%
GC暂停时间
85ms
23ms
-72.9%
95%响应时间
187ms
62ms
-66.8%
通过这一系列优化,我们不仅解决了内存问题,还显著提升了服务响应速度。最重要的是,高峰期不再触发OOM警告,系统稳定性大幅提升。
七、踩坑经验与最佳实践
在进行内存优化的过程中,我们踩过不少坑,总结出一些宝贵经验。
切片预分配容量的重要性
问题:频繁追加元素导致切片不断扩容,产生大量临时对象。
最佳实践:
// 错误示范:未预分配容量
func BuildResponseBad(ids []int) []string {
var result []string // 初始容量为0
for _, id := range ids {
// 频繁扩容和内存复制
result = append(result, fmt.Sprintf("ID-%d", id))
}
return result
}
// 正确示范:预分配合适容量
func BuildResponseGood(ids []int) []string {
result := make([]string, 0, len(ids)) // 预分配足够容量
for _, id := range ids {
// 不会触发扩容
result = append(result, fmt.Sprintf("ID-%d", id))
}
return result
}
实测:处理1000个元素时,预分配容量的版本内存分配减少了93%!
避免不必要的内存逃逸
内存逃逸指变量本应在栈上分配,但因某些原因必须分配在堆上。识别和减少逃逸能显著提升内存效率。
常见的逃逸场景:
返回局部变量的指针接口类型转换闭包捕获变量超过阈值的大对象
// 逃逸案例:返回局部变量指针
func NewUserEscaped() *User {
// user将逃逸到堆上
user := User{Name: "Tom"}
return &user
}
// 避免逃逸:直接返回值
func NewUserNoEscape() User {
// user在栈上分配
user := User{Name: "Tom"}
return user
}
// 确实需要指针时,可以让调用者传入
func FillUser(user *User) {
user.Name = "Tom"
}
查看逃逸分析:
go build -gcflags="-m -l" main.go
字符串处理的内存陷阱
问题:Go中字符串是不可变的,每次修改都会创建新的字符串。
最佳实践:
使用strings.Builder进行拼接对于已知长度的拼接,预先Grow重用Builder对象减少分配
// 重用Builder的例子
var builderPool = sync.Pool{
New: func() interface{} {
return &strings.Builder{}
},
}
func FormatMessage(name, address string) string {
// 从对象池获取Builder
b := builderPool.Get().(*strings.Builder)
b.Reset() // 重要:重置复用的Builder
defer builderPool.Put(b)
// 预估容量
b.Grow(len(name) + len(address) + 20)
b.WriteString("Name: ")
b.WriteString(name)
b.WriteString("nAddress: ")
b.WriteString(address)
return b.String()
}
结构体字段对齐优化
问题:结构体字段排列不当会导致内存浪费。
原理:Go会按照一定规则对结构体字段进行内存对齐,不同类型的字段有不同的对齐要求。
最佳实践:
// 内存浪费的结构体:48字节
type WastefulStruct struct {
a bool // 1字节,但会占用8字节
b int64 // 8字节
c bool // 1字节,但会占用8字节
d int32 // 4字节,但会占用8字节
e byte // 1字节,但会占用8字节
f int64 // 8字节
}
// 优化后的结构体:24字节
type OptimizedStruct struct {
b int64 // 8字节
f int64 // 8字节
d int32 // 4字节
a bool // 1字节
c bool // 1字节
e byte // 1字节
// 1字节填充
}
可以使用以下工具查看结构体大小和对齐情况:
go install golang.org/x/tools/go/analysis/passes/fieldalignment/cmd/fieldalignment@latest
fieldalignment ./...
sync.Pool在高频对象分配中的应用
问题:频繁创建和销毁临时对象会增加GC压力。
解决方案:使用sync.Pool重用对象,减少分配和回收。
适用场景:
// 为HTTP处理创建请求上下文对象池
var contextPool = sync.Pool{
New: func() interface{} {
return &RequestContext{
buffer: make([]byte, 0, 4096),
params: make(map[string]string),
}
},
}
func Handler(w http.ResponseWriter, r *http.Request) {
// 获取上下文对象
ctx := contextPool.Get().(*RequestContext)
defer func() {
// 清理对象状态
ctx.buffer = ctx.buffer[:0]
for k := range ctx.params {
delete(ctx.params, k)
}
// 放回池中
contextPool.Put(ctx)
}()
// 使用上下文处理请求
// ...
}
️ 注意事项:放回池前必须清除敏感数据,且不要假设从池中取出的对象状态是干净的。
八、高级主题:内存使用与CPU消耗的权衡
优化内存使用时,我们常需要在内存和CPU之间做出权衡,就像在计划旅行时需要权衡时间成本和金钱成本一样。
空间换时间的决策依据
何时值得用内存换取性能:
CPU成为瓶颈:当CPU利用率接近100%,而内存有富余时响应时间敏感:对用户交互的实时性要求高计算成本高昂:某些复杂计算的重复执行成本远高于缓存成本
何时应该减少内存使用:
内存压力大:系统频繁触发GC或接近OOM多租户环境:每个用户的内存使用需要控制在合理范围冷数据占比大:缓存命中率低,维护缓存的开销大于收益
让我们通过一个缓存决策示例来说明:
// 内存与CPU的权衡示例
type ComputeService struct {
// 决策参数
memoryLimit int64 // 内存限制(bytes)
cpuCost time.Duration // 单次计算耗时
hitRatio float64 // 预期缓存命中率
itemSize int64 // 单个结果占用内存(bytes)
// 缓存实现
cache map[string][]byte
cacheMutex sync.RWMutex
currentMemory int64
}
// 决策是否应该缓存结果
func (s *ComputeService) shouldCache(key string, result []byte) bool {
// 如果内存已经接近限制,不缓存
if s.currentMemory > s.memoryLimit*0.9 {
return false
}
// 如果结果过大,不缓存
if int64(len(result)) > s.itemSize*2 {
return false
}
// 如果计算足够快,且结果较大,不缓存
if s.cpuCost < 10*time.Millisecond && int64(len(result)) > s.itemSize {
return false
}
return true
}
缓存策略对内存的影响
不同的缓存策略会对内存使用和性能产生不同影响。
常见缓存策略对比:
策略内存使用CPU使用适用场景Go实现
LRU(最近最少使用)
固定上限
访问模式有时间局部性
github.com/hashicorp/golang-lru
LFU(最不常使用)
固定上限
访问频率分布不均
github.com/dgryski/go-tinylfu
TTL(过期时间)
不定,需GC
数据有明确的有效期
自定义map+时间戳
分段缓存
固定上限
高并发读写场景
github.com/patrickmn/go-cache
实现一个带内存感知的TTL缓存:
// 内存感知的TTL缓存
type MemoryAwareTTLCache struct {
data map[string]cacheItem
mu sync.RWMutex
maxMemory int64
currentUsage int64
}
type cacheItem struct {
value []byte
size int64
expireTime time.Time
}
// 添加项目到缓存,如果内存不足则清除旧项目
func (c *MemoryAwareTTLCache) Set(key string, value []byte, ttl time.Duration) {
c.mu.Lock()
defer c.mu.Unlock()
size := int64(len(value) + len(key))
// 如果存在旧值,先减去它的大小
if old, exists := c.data[key]; exists {
c.currentUsage -= old.size
}
// 检查是否会超出内存限制
if c.currentUsage+size > c.maxMemory {
c.evictOldest()
}
// 添加新项目
c.data[key] = cacheItem{
value: value,
size: size,
expireTime: time.Now().Add(ttl),
}
c.currentUsage += size
}
// 清除最早过期的项目直到有足够空间
func (c *MemoryAwareTTLCache) evictOldest() {
// 按过期时间排序
type expireEntry struct {
key string
expireTime time.Time
}
entries := make([]expireEntry, 0, len(c.data))
for k, v := range c.data {
entries = append(entries, expireEntry{k, v.expireTime})
}
sort.Slice(entries, func(i, j int) bool {
return entries[i].expireTime.Before(entries[j].expireTime)
})
// 清除约20%的空间或直到足够
targetUsage := c.maxMemory * 8 / 10
for i := 0; i < len(entries) && c.currentUsage > targetUsage; i++ {
item := c.data[entries[i].key]
c.currentUsage -= item.size
delete(c.data, entries[i].key)
}
}
GC调优参数的实战应用
Go的GC是自动的,但提供了一些参数允许我们进行微调:
GOGC环境变量:控制GC触发阈值,默认为100,表示当新分配的内存达到上次GC后存活对象的100%时触发。
在代码中动态调整GOGC:
import "runtime/debug"
func AdjustGCBasedOnLoad(memoryPressure float64) {
// 根据内存压力调整GC参数
if memoryPressure > 0.8 {
// 高内存压力,更频繁GC
debug.SetGCPercent(50)
} else if memoryPressure > 0.5 {
// 中等内存压力,默认GC
debug.SetGCPercent(100)
} else {
// 低内存压力,减少GC
debug.SetGCPercent(150)
}
}
实战场景:内存使用峰谷调节
// 根据请求流量调整GC策略
type AdaptiveServer struct {
currentQPS int32
peakQPS int32
lowWatermark int32
highWatermark int32
defaultGCPercent int
}
func (s *AdaptiveServer) ServeHTTP(w http.ResponseWriter, r *http.Request) {
// 更新QPS计数
atomic.AddInt32(&s.currentQPS, 1)
defer atomic.AddInt32(&s.currentQPS, -1)
// 调整GC策略
s.adjustGC()
// 处理请求...
}
func (s *AdaptiveServer) adjustGC() {
current := atomic.LoadInt32(&s.currentQPS)
// 更新峰值
if current > s.peakQPS {
s.peakQPS = current
}
// 根据负载调整GC
if current > s.highWatermark {
// 高负载,减少GC频率以优先处理请求
gcPercent := s.defaultGCPercent + 50
debug.SetGCPercent(gcPercent)
} else if current < s.lowWatermark {
// 低负载,增加GC频率回收内存
gcPercent := s.defaultGCPercent - 20
if gcPercent < 20 {
gcPercent = 20 // 防止设置过低
}
debug.SetGCPercent(gcPercent)
} else {
// 恢复默认值
debug.SetGCPercent(s.defaultGCPercent)
}
}
九、自动化内存基准测试与CI/CD集成
要构建可持续维护的高质量Go应用,自动化的内存监控至关重要。这就像定期体检一样,可以及早发现问题。
构建持续的内存性能监控系统
一个完整的内存性能监控系统应包含以下部分:
基准测试套件:覆盖关键功能的内存性能测试自动执行机制:定期或在代码变更时触发测试结果收集与存储:保存历史数据用于比较分析与告警系统:发现异常并通知团队
下面是一个基本的内存基准测试套件示例:
// benchmark_suite_test.go
package benchmark
import (
"testing"
"time"
"yourapp/api"
"yourapp/db"
"yourapp/service"
)
// 初始化测试环境
func setupBenchmarkEnv() (*service.Service, func()) {
// 设置测试数据库
testDB := db.NewTestDB()
// 创建服务实例
svc := service.New(testDB)
// 返回清理函数
cleanup := func() {
testDB.Close()
}
return svc, cleanup
}
// API端点基准测试
func BenchmarkAPIEndpoints(b *testing.B) {
svc, cleanup := setupBenchmarkEnv()
defer cleanup()
b.Run("ListProducts", func(b *testing.B) {
for i := 0; i < b.N; i++ {
svc.ListProducts("electronics", 50)
}
})
b.Run("GetProductDetail", func(b *testing.B) {
for i := 0; i < b.N; i++ {
svc.GetProductDetail(123)
}
})
// 更多API测试...
}
// 并发基准测试
func BenchmarkConcurrentOperations(b *testing.B) {
svc, cleanup := setupBenchmarkEnv()
defer cleanup()
b.Run("ConcurrentReads", func(b *testing.B) {
b.RunParallel(func(pb *testing.PB) {
for pb.Next() {
svc.ListProducts("electronics", 20)
}
})
})
// 更多并发测试...
}
// 内存泄漏测试
func BenchmarkMemoryLeak(b *testing.B) {
svc, cleanup := setupBenchmarkEnv()
defer cleanup()
// 记录初始内存
var m runtime.MemStats
runtime.ReadMemStats(&m)
initialAlloc := m.Alloc
// 执行多次操作
for i := 0; i < 1000; i++ {
svc.ProcessBatchOperation()
}
// 手动触发GC
runtime.GC()
// 检查最终内存
runtime.ReadMemStats(&m)
finalAlloc := m.Alloc
// 记录增长,但不作为失败条件(这只是观察值)
b.ReportMetric(float64(finalAlloc-initialAlloc), "B/mem_growth")
}
性能劣化自动预警机制
为了及早发现内存性能问题,我们可以构建自动预警机制:
// benchmark_compare.go
package main
import (
"encoding/json"
"fmt"
"os"
"os/exec"
"strings"
)
type BenchmarkResult struct {
Name string
Operations int
NsPerOp float64
BytesPerOp int
AllocsPerOp int
MemGrowth float64
}
func main() {
// 运行基准测试并捕获输出
cmd := exec.Command("go", "test", "-bench=.", "-benchmem", "./...")
output, err := cmd.CombinedOutput()
if err != nil {
fmt.Printf("Failed to run benchmarks: %vn", err)
os.Exit(1)
}
// 解析结果
currentResults := parseBenchmarkOutput(string(output))
// 加载历史结果
historicalResults := loadHistoricalResults()
// 比较结果
degradations := compareResults(currentResults, historicalResults)
// 如果发现性能劣化,发出警告
if len(degradations) > 0 {
fmt.Println("PERFORMANCE DEGRADATION DETECTED:")
for _, d := range degradations {
fmt.Println(d)
}
// 可以集成发送邮件或Slack通知
os.Exit(1)
}
// 保存当前结果作为历史记录
saveResults(currentResults)
}
// 比较基准测试结果,返回劣化项
func compareResults(current, historical map[string]BenchmarkResult) []string {
var degradations []string
for name, curr := range current {
if hist, exists := historical[name]; exists {
// 内存分配增加20%以上视为劣化
if float64(curr.BytesPerOp) > float64(hist.BytesPerOp)*1.2 {
degradations = append(degradations,
fmt.Sprintf("%s: Memory usage increased by %.2f%% (from %d to %d bytes/op)",
name,
float64(curr.BytesPerOp-hist.BytesPerOp)/float64(hist.BytesPerOp)*100,
hist.BytesPerOp,
curr.BytesPerOp))
}
// 分配次数增加视为劣化
if curr.AllocsPerOp > hist.AllocsPerOp {
degradations = append(degradations,
fmt.Sprintf("%s: Allocs increased from %d to %d per op",
name, hist.AllocsPerOp, curr.AllocsPerOp))
}
// 内存泄漏测试特别关注
if strings.Contains(name, "MemoryLeak") && curr.MemGrowth > hist.MemGrowth*1.1 {
degradations = append(degradations,
fmt.Sprintf("%s: Potential memory leak detected, growth increased by %.2f%%",
name,
(curr.MemGrowth-hist.MemGrowth)/hist.MemGrowth*100))
}
}
}
return degradations
}
基于历史数据的性能趋势分析
仅比较最近两次结果可能会遗漏渐进式劣化。通过收集长期数据并分析趋势,我们能够更全面地了解应用内存性能的变化。
可以使用如下工具构建趋势分析系统:
时序数据库(如InfluxDB、Prometheus)存储历史性能数据可视化工具(如Grafana)展示性能变化趋势统计分析识别异常和趋势变化
趋势图示例:
集成到CI/CD流程:
# .github/workflows/benchmark.yml
name: Memory Benchmark
on:
push:
branches: [ main ]
pull_request:
branches: [ main ]
jobs:
benchmark:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Set up Go
uses: actions/setup-go@v3
with:
go-version: '1.21'
- name: Run benchmarks
run: go test -run=^$ -bench=. -benchmem ./... > benchmark.txt
- name: Compare with previous benchmark
run: |
# 下载历史数据
curl -sL https://example.com/benchmarks/latest.txt -o previous.txt || true
# 执行比较
go run ./tools/bench-compare/main.go benchmark.txt previous.txt
- name: Upload benchmark results
uses: actions/upload-artifact@v3
with:
name: benchmark-results
path: benchmark.txt
- name: Store benchmark result
if: github.event_name == 'push' && github.ref == 'refs/heads/main'
run: |
# 上传到存储服务或GitHub Release
curl -X POST -F file=@benchmark.txt https://example.com/benchmarks/upload
十、总结与展望
通过这次深入探讨Go程序内存基准测试与优化,我们不仅学习了理论知识,还通过实战案例获得了宝贵的实践经验。
内存基准测试的核心价值
内存优化不仅是技术问题,更是业务价值的保障。良好的内存使用能够:
提升用户体验:减少延迟和卡顿,提高应用响应速度降低运营成本:更高效的内存使用意味着可以用更少的服务器资源处理相同负载增强系统弹性:避免内存泄漏和OOM错误,提高系统稳定性支持业务扩展:优化的内存使用为业务增长提供更多容量空间
正如中国古语所说:“工欲善其事,必先利其器”。掌握和应用内存基准测试工具,是优化Go程序内存使用的关键一步。
Go内存管理演进趋势
Go语言的内存管理机制在不断演进,未来发展趋势包括:
更智能的GC:未来Go可能采用分代GC或混合GC策略,进一步降低GC暂停时间更精细的内存控制:为特定场景提供更多手动内存管理选项,满足极端性能需求更好的逃逸分析:编译器可能会提供更智能的逃逸分析,减少堆分配内存压缩技术:引入内存压缩技术,提高内存利用率 未来学习与实践建议
作为Go开发者,建议从以下几个方面继续提升内存优化能力:
深入理解Go运行时:学习Go的内存分配器和GC实现细节建立基准测试文化:在团队中推广性能测试驱动开发方法论研究大规模系统:学习大型Go项目(如Docker、Kubernetes)的内存优化经验关注最新进展:跟踪Go语言在内存管理方面的最新改进
最后,记住性能优化的第一原则:先测量,再优化。没有基准测试的优化往往是猜测,而不是工程。通过持续的测量和改进,我们能够构建出既高效又可靠的Go应用。
附录:实用工具与参考资源 推荐工具清单 工具用途链接
pprof
性能分析与可视化
内置于Go标准库
benchstat
基准测试结果对比
golang.org/x/perf/cmd/benchstat
go-torch
火焰图生成工具
github.com/uber/go-torch
goleak
检测goroutine泄漏
github.com/uber-go/goleak
aligncheck
结构体内存对齐检查
github.com/opennota/check
memvis
内存分配可视化
github.com/bradleyjkemp/memviz
进阶学习资源 《Go语言高级编程》- 内存管理与性能优化章节Go Blog: Profiling Go ProgramsGo Blog: Allocation Efficiency in High-Performance Go ServicesGo语言原本 - 详解Go内存分配器Go GC: Prioritizing low latency and simplicity 相关社区讨论 Golang Weekly Newsletter - 定期更新包含性能优化技巧Reddit r/golang - 频繁有关于内存优化的讨论Go Forum (forum.golangbridge.org) - 有专门的性能优化板块GopherCon 会议视频 - 包含许多关于性能优化的演讲
通过持续学习和实践,相信你能够掌握Go内存优化的精髓,写出既高效又优雅的代码!